Hello scikit-learn
O scikit-learn é um das principais ferramentas que usamos para o Aprendizado de máquina. É um pacote em Python com uma rica documentação disponível em : https://scikit-learn.org/ .
Além de ferramentas para usarmos nos estudos e aplicações de machine Learning, como os principais algoritmos para resolver problemas de cluster, classificação ou regressão, ele também possui dados de testes, os chamados Toys datasets. Que envolve diferentes contextos, como tamanho de pétalas de flores, pacote iris, ou informações sobre pacientes diabéticos. Ao todo existem 6 pacotes “toys” para explorar.
Todo o código a seguir, esta disponível em um google colab, clicando aqui
Para instalar esse pacote podemos usar o pip
pip install -U scikit-learnAssim como todos os pacotes em python, para usa-lo precisa importar.
import sklearnPara utilizar um dataset personalizado, utiliza a seguinte função.
from sklearn import datasetsJá para utilizar uma base Toy, como o conjunto de dados sobre flores utiliza:
from sklearn.datasets import load_irisAssim, como a documentação mostra, esse conjunto de dados, possui altura e largura das pétalas de flores. Podemos importar de duas formas um dataset, a primeira:
Importando dataset sem X, y
# carregar os dados para uma vari'svel
dados = load_iris()
# Quero saber os valores, numéricos, da classificação da linha 1 ,10, 100
dados.target[[1,10,100]]
array([0, 0, 2])Se quisermos ver os valores de uma linha especifica , utilizamos a função:
dados.data[[1,10,100]]
array([[4.9, 3. , 1.4, 0.2], [5.4, 3.7, 1.5, 0.2], [6.3, 3.3, 6. , 2.5]])Se quisermos ver os títulos de cada coluna, utilizamos o seguinte comando:
list( dados.feature_names)
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']Se quiser saber os target_names, isto é, os nomes das classificações, utilizo a seguinte função:
list(dados.target_names)
['setosa', 'versicolor', 'virginica']Como temos os target_names, esse modelo fornece um treino supervisionado, ja falamos sobre isso nesse post.
A Parte DATA: São as características dos dados, as features.
A parte TARGET, é o rótulo, no caso, é o que queremos descobrir.
dados.target
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])0,1,2 Corresponde, ao dados.target_names, respectivamente.
Importando dataset com X, y.
Na documentação, sempre existe essa notação. o X é o data, características, o Y é o target, o que queremos prever.
Lembra da fórmula:
𝑦=𝑓(𝑥)
então, qual é o Y, quando informamos x ? Isso é o que nosso algoritmo quer descobrir. Exatamente, como na fórmula.
Para utilizar essa notação , o load_iris, irá mudar.
X, y = load_iris(return_X_y=True)nessa hora, o X == dados.data e o y == dados.target
Convertendo em PANDAS
Você pode precisar passar o seu dataset scikit-learn para um dataframe PANDAS, ele é mais amigável e popular, na análise de dados, e pode ser útil na hora de apresentar os dados. Para fazer isso, import o pandas.
import pandas as pdConverta seu dataSet em dataFrame
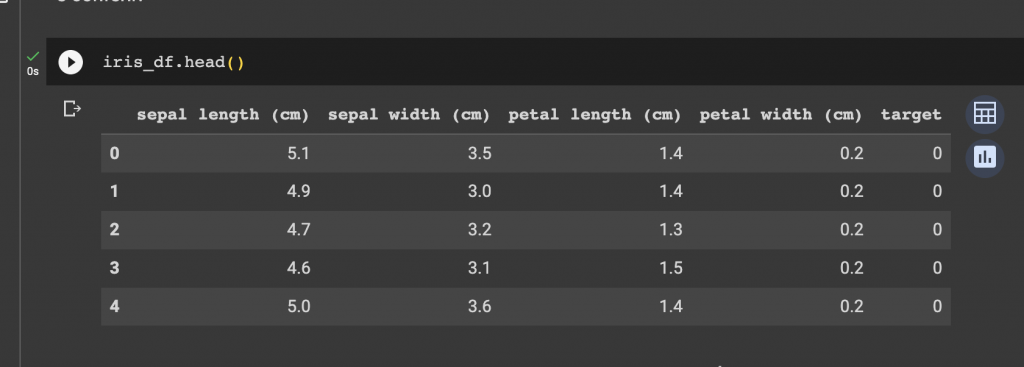
iris_df = pd.DataFrame(data= dados.data, columns=dados.feature_names)iris_df[‘target’] = dados.target
e confira
Você quer o nome? podemos add também um coluna mais amigável ainda. Com uma função do pandas:
iris_df['target_names'] = pd.Categorical.from_codes(dados.target, dados.target_names)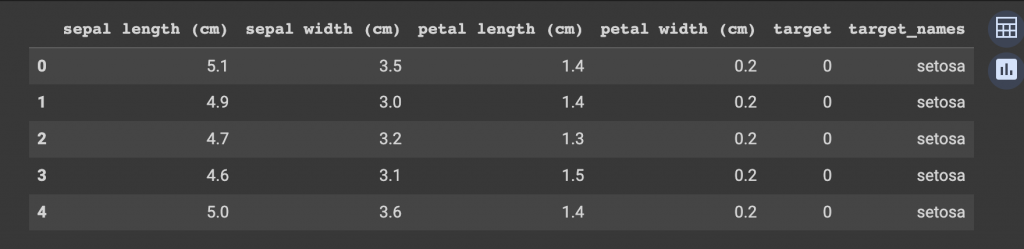
Podemos fazer um gráfico, para ver e entender a utilidade dessa conversão.
Para conseguir plotar gráficos aqui , precisamos de uma notação.
%matplotlib inlineiris_df.plot.scatter( 'sepal length (cm)', 'sepal width (cm)', c='target')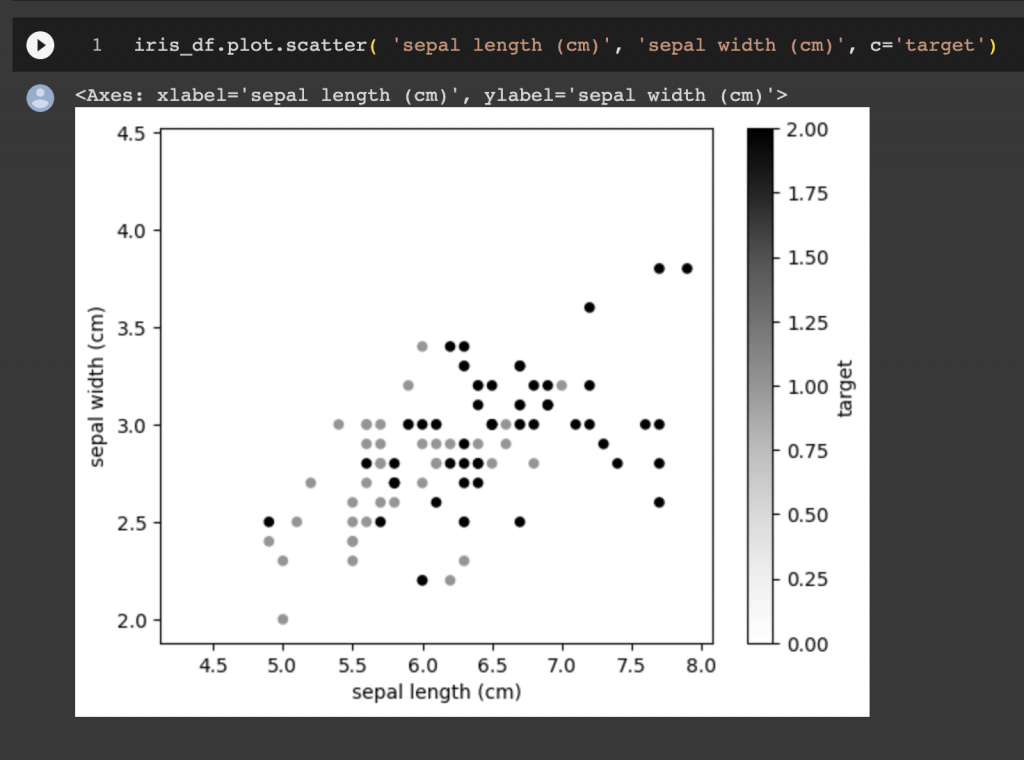
Conjuntos de treinamento e teste
Para separar seus dados, podemos dividir o grande conjunto em duas partes, para testarmos e validamos nossos algoritmos. O próprio scikit-learn ja faz isso para você. Conseguindo determinar quais porcentagens vão para cada conjunto. Utilizando o train_test_split, test_size, é a porcentagem das divisões, e o random_state, é uma semente para pegar aleatoriamente os elementos, caso o data_frame esteja ordenado.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state=22)