Hello Spacy – Processamento de Linguagem Natural
Quando falamos de linguagem natural, podemos imaginar qualquer dado não estruturado. Então vários comentários em um post, tweets, sentenças judiciais, prontuários médicos, dentre outras coisas que estão escritas de maneira livre. Sem nenhuma organização fortemente estruturada, como um banco de dados.
Nos post anteriores, ja vimos algumas formas de usar o scikit-learn para aprendizado de máquina, através desses dados estruturados. Mas, quando o dado não é estruturado, como faremos para extrair informações dele, sentido.
Na análise de linguagem natural podemos seguir por dois caminhos, a análise semântica e a morfológica.
- Morfológica: Estuda das palavras e classes gramaticais. Ex.: Plural ou singular? Verbo ou adjetivo? Qual o tempo verbal? É Masculino ou feminino ?
- Sintática: Função em que as palavras tem em uma frase.
Analise morfológica:
Uma forma de analisar um texto é de forma morfológica. Além do sentido que as palavras possuem em um texto de forma conjunta, podemos analisar o sentido dela individual, como por exemplo gênero, se é singular ou plural, dentre outras formas. Nessa sessão iremos explorar esse tipo de análise.
- Atributos léxicos
- Tagueamento POS: Parte do discurso.
- Lematização Simplificar, ficando com o radical por exemplo , gatos, gata, gatinhos, é a mesma coisa.
- Dependencias : Relações entre as palavras. ( Ramon foi embora | alguém foi embora… | no caso, ramon )
- StopWords: Palavras irrelevantes, as pessoas foram embora. Esse “as” pode ser removido, sem interferir no sentido da frase.
Iniciando com Spacy

Para começar nossa jornada no PLN precisamos instalar algumas coisas, como o spacy esta em binário, podemos verificar se o setuptools weel esta instalado antes, em seguida instalar o spacy e depois fazer o download do pacote da linguagem que desejamos . Esse tutorial pode ser acessado no site do spacy: https://spacy.io/usage . Baixamos esse pacote de idioma, pois é um modelo previamente treinado. E deve ser baixado de acordo com o idioma que você esta trabalhando. Outros modelos estão disponíveis aqui: https://spacy.io/models . Geralmente, cada modelo possui um sm, md, e lg. Onde o lg é o mais preciso e o sm o mais eficiente.
pip install -U pip setuptools wheel
pip install -U spacy
python -m spacy download pt_core_news_smApós instalado as ferramentas podemos começar a entender como o spacy funciona.
from spacy import blank
npl = blank('pt')
doc = npl('Ramon foi a escola.')
#token
print(doc[0])
print(doc[-1])
#span
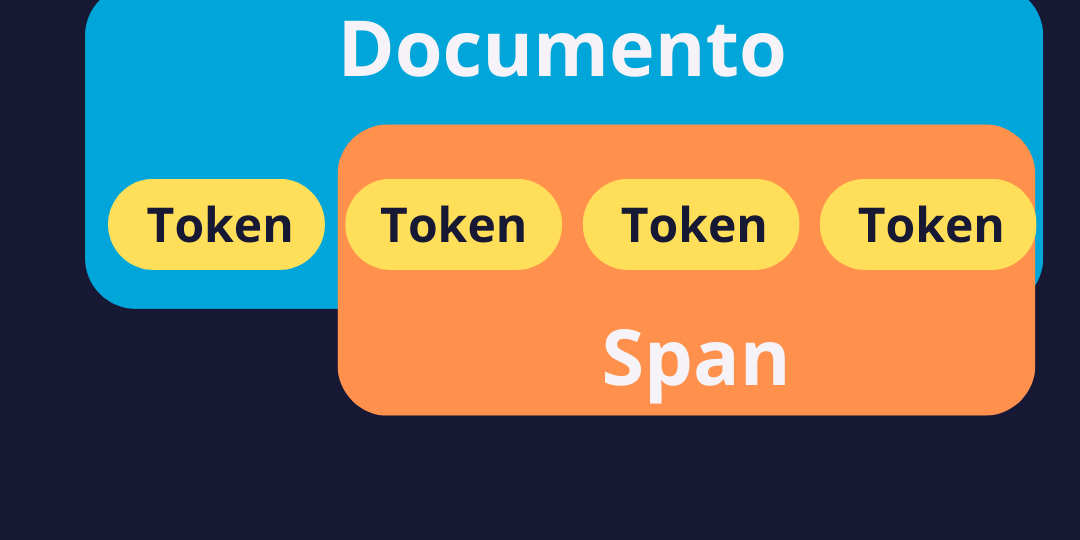
print(doc[0:3])Importando o blank, damos início a uma documento vazio em português. O Próprio Spacy ja faz essa separação em tokens. O documento, tem vários tokens, um conjunto de token é um span. Como ilustra a imagem a seguir. Até agora não existe nenhuma interpretação de texto. Somente separou os tokens.
Podemos explorar as propriedades das palavras, se é uma stop word, se é pontuação, verbo.. dentre outras coisas.
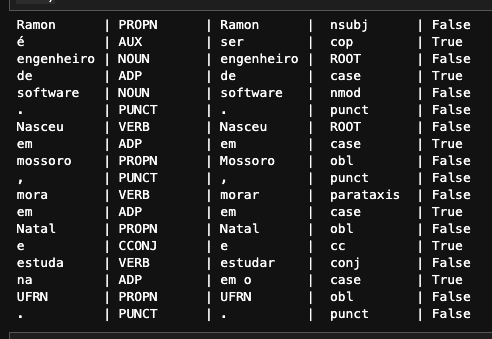
doc = nlp('Ramon é engenheiro de software. Nasceu em mossoro,mora em Natal e estuda na UFRN.')
for token in doc:
print(
'{:10} | {:10} | {:10} | {:10} | {}'. format( token.text, token.pos_, token.lemma_, token.dep_, token.is_stop)
)
Para identificar o que significa uma atribuição dessas, o spacy explica.
from spacy import explain
explain('PROPN')
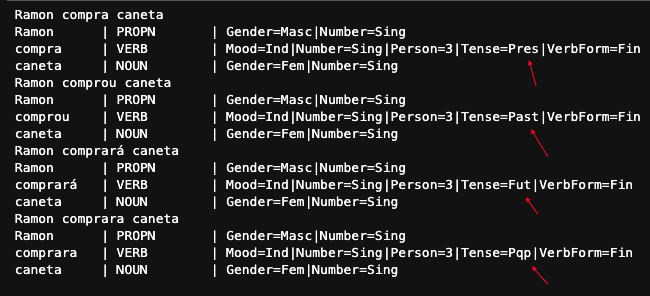
#'proper noun'O tempo verbal, por exemplo, pode ser útil na identificação de padrões em frases, o Spacy consegue identifica isso, dessa forma, na propriedade tense.
doc = nlp('Ramon compra caneta')
print(doc)
for t in doc:
print(
'{:10} | {:10} | {}'. format( t.text, t.pos_, t.morph)
)
doc = nlp('Ramon comprou caneta')
print(doc)
for t in doc:
print(
'{:10} | {:10} | {}'. format( t.text, t.pos_, t.morph)
)
doc = nlp('Ramon comprará caneta')
print(doc)
for t in doc:
print(
'{:10} | {:10} | {}'. format( t.text, t.pos_, t.morph)
)
doc = nlp('Ramon comprara caneta')
print(doc)
for t in doc:
print(
'{:10} | {:10} | {}'. format( t.text, t.pos_, t.morph)
)
Identificar entidades, como pessoas, países e orgãos é muito importante em algumas análises. O Spacy consegue identificar. Vamos pegar o poema Quadrilha, Carlos Drummond de Andrade. Possui muitos nomes, vamos ver como o Spacy mostra essas entidades.
text = '''
João amava Teresa que amava Raimundo
que amava Maria que amava Joaquim que amava Lili
que não amava ninguém.
João foi para os Estados Unidos, Teresa para o convento,
Raimundo morreu de desastre, Maria ficou para tia,
Joaquim suicidou-se e Lili casou com J. Pinto Fernandes
que não tinha entrado na história
'''
doc = nlp(text)
displacy.render(doc, style="ent", jupyter=True)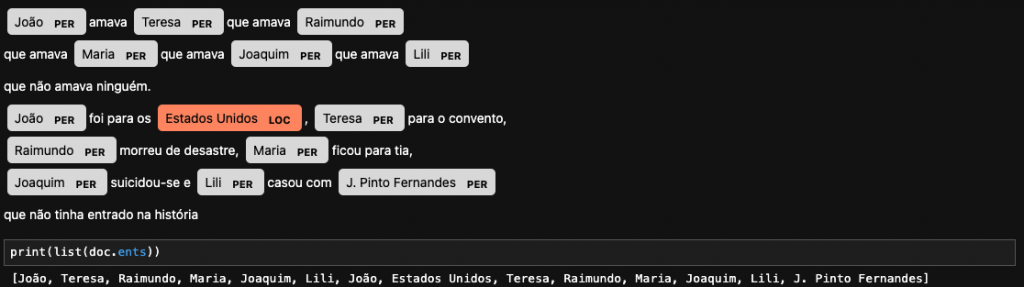
As palavras possuem relação entre si, conseguimos ver essa relacionamento através da renderização das dependências.
from spacy import displacy , load
doc = nlp('Ramon é engenheiro de software. Nasceu em mossoro,mora em Natal e estuda na UFRN.')
displacy.render(doc, style="dep", jupyter=True)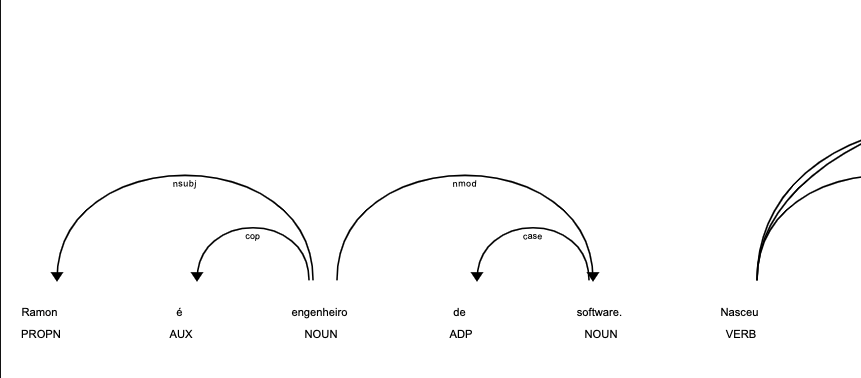
Esse foi um resumo de algumas funções do Spacy. No próximo post, criaremos uma aplicação de análise de tweets tóxicos.
Até lá!
Muito bacana! Valeu por todo conhecimento externado.