Conceito da Árvore de decisão – Aprendizado de máquina
O Algoritmo de árvore de decisão é bastante popular, e possui representações gráficas de como o algoritmo esta realizando as decisões. Muito bom para ajudar o entendimento das operações que ele realiza, e prever possíveis falhas, em casos mais críticos. Dessa forma, adicionando mais cenários desse tipo para o treinamento.
Neste post vamos utilizar uma situação simples, com poucos nós. Para entendermos como ele funciona, e em quais situações ele é uma boa escolha, no próximo post utilizaremos datasets maiores, com mais decisões, além de Sim/Não.
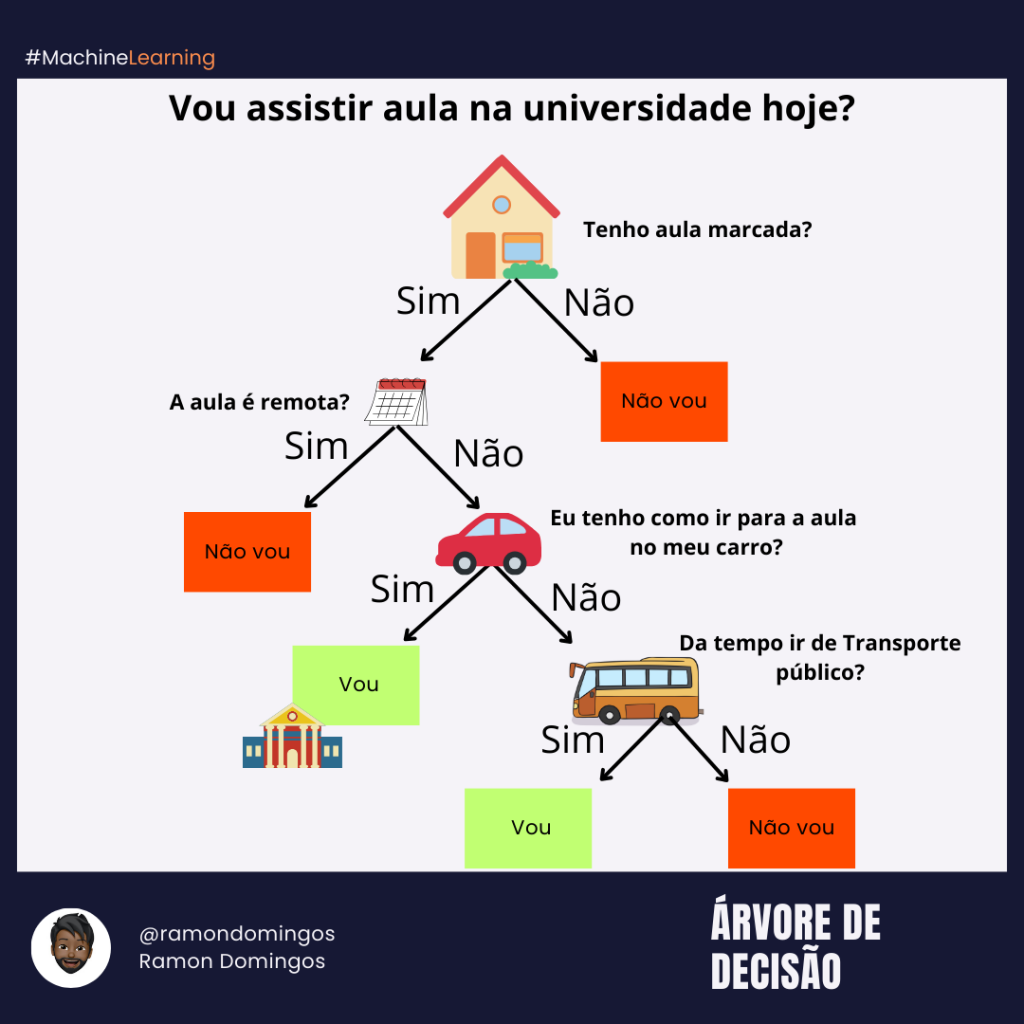
No geral esse algoritmo busca classificar um registro ( problemas de classificação) ou estimar um valor ( problemas de regressão). Como vemos nessa imagem , cada pergunta, chamadas de nó decisão, respondemos SIM ou NÃO, a primeira pergunta, o nó inicial é o nó raiz e o último, com a resposta, é o nó folha. Em inglês, Decision node, Chance node, Endpoint Node.
Mas como sair de uma simplesmente diagramação visual e chegar num modelo?
O sckit-learn faz esse treinamento, além de exibir uma representação visual das decisões como essa:

Preparei um colab com esses exemplos que teremos nesse post.
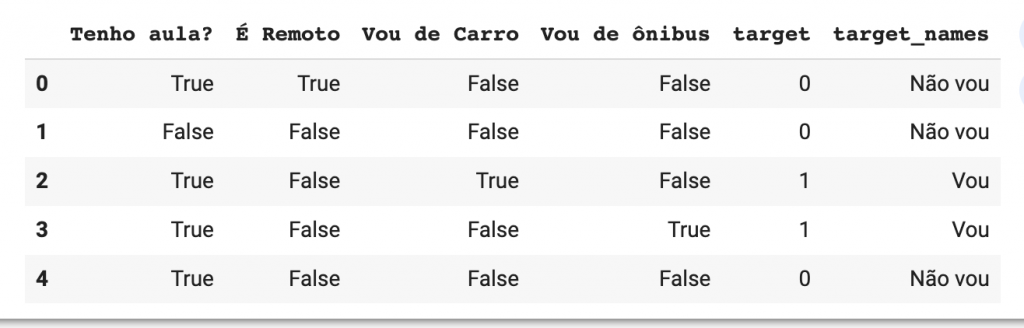
Inicialmente, preparei um array, usando numPy, baseado nessa situação, e exibir a tabela
import pandas as pd
import numpy as np
# Criando um array de resultados
numpy_array = np.array([
[True,True,False,False,False], [False,False,False,False,False],
[True,False,True,False,True], [True,False,False,True,True],
[True,False,False,False,False]])
# Convertendo em Pandas dataFrame
df = pd.DataFrame(numpy_array, columns=['Tenho aula?', 'É Remoto', 'Vou de Carro', 'Vou de ônibus', 'target'])
df["target"] = df["target"].astype(int)
df['target_names']= pd.Categorical.from_codes (df["target"], ['Não vou', 'Vou'])
# Exibindo
df.head()Ficou assim:
Em seguida, usando o sckitLearn para criar uma classificador, treinar o modelo e criar a árvore de decisão, em seguida apresento aquela representação gráfica. Mostrada inicialmente.
from sklearn import tree
clf = tree.DecisionTreeClassifier( random_state=42)
clf = clf.fit(dados, df.target)
tree.plot_tree(clf)No próximo post, vamos utilizar algum Toy dataset para esse algoritmo.
[…] post anterior vimos uma aplicação simples do algoritmo Árvore de decisão, para entender se iríamos ou não […]
[…] Fonte: RamonDomingos. […]