Removendo outliers de uma base de dados
Os outliers de uma base de dados são aqueles valores que estão muito distante da maioria dos dados. Esses valores podem fazer com que uma média fique muito maior do que realmente ela seja, sempre é importante analisar os dados que possuímos no início do processo . Olhar para mediana, e plotar gráficos com BoxPlot, é uma forma de identificar a distribuição da sua base de dados.
Alguns conceitos:
- Média: Soma de todos os valores, dividido pela quantidade de elementos.
- Mediana: Exatamente o valor do meio dos dados, no caso de quantidade pares, é a média dos 2 valores.
- Outlier: Ponto fora da Curva/ distribuição da maioria do dados.
Vamos analisar o seguinte cenário hipotético, temos uma base de dados referente a internações em um hospital, com os seguintes dados:
| Id | Idade | Dias Internados | Quantidade de vezes internada |
| 1 | 21 | 1 | 1 |
| 2 | 20 | 1 | 1 |
| 3 | 19 | 2 | 1 |
| 4 | 45 | 7 | 4 |
Dados:
- Dias Internados:
- Média: 2.75 dias.
- Mediana:1.5 dias.
- Idade:
- Média: 26 anos.
- Mediana:20,5 anos.
Da mesma forma que um dado isolado subiu a média para próximo de 3 dias, quando a maioria das internações duraram 1 ou 2 dias, e a media de idade para 26, quando a maioria estava próximo de 20. Uma base de dados com valores fora da curva, podem fazer seu algoritmo de aprendizagem de máquina, predizer de maneira menos assertiva, levando em considerações, essas exceções.
Uma técnica bastante utilizada é através da Identificação desses valores através de intervalos Interquartis, o boxPlot é um excelente meio de fazer essa identificação.
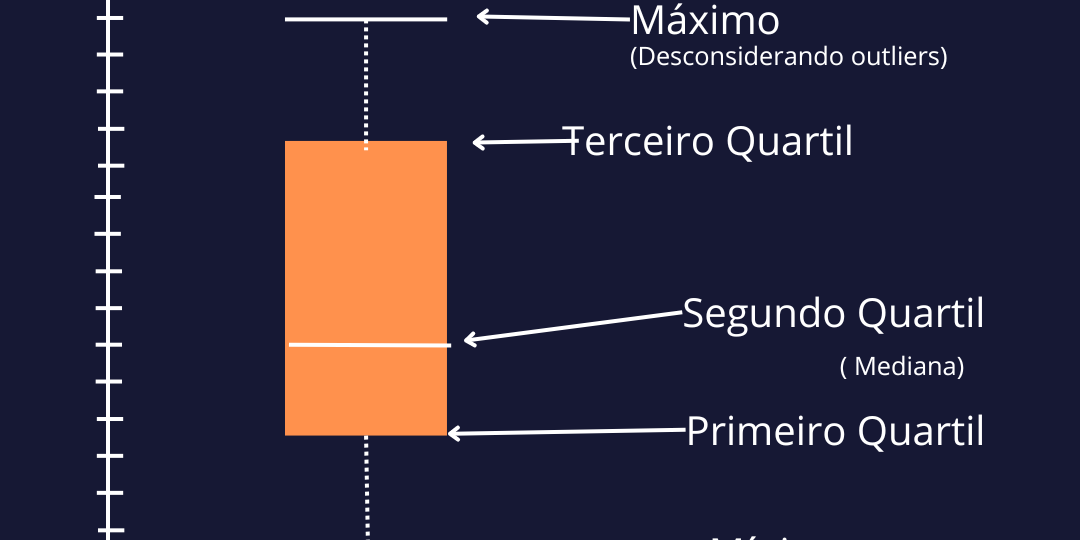
O boxplot

Nessa representação visual, temos os intervalos, o primeiro quartil, é representado por 25%, o terceiro quartil, por 75%. Quando é subtraído Q3 e Q1, temos o Intervalo Interquartil (IQR). Esse valor, serve de referencia para se fazer os limites de máximo e mínimo. Qualquer valor além disso, é considerado um outlier, e é uma boa prática remove-los. O limite inferior se da por Q1-1.5*IQR, e o superior Q3+1.5*IQR.
Essa etapa de pré-processamento, é muito importante para aumentar a acurácia de um algoritmo. No entanto, de nenhuma forma os dados devem ser alterados, o ideal é remove-los da base de treinamento. Nesse colab existe essa etapa de análise e remoção de outliers.
Após identificar os outliers, o próximo passo é remove-los.
for key in df.columns.values.tolist():
Q1 = df[key].quantile(0.25)
Q3 = df[key].quantile(0.75)
IQR = Q3 - Q1 #IQR is interquartile range.
filter = (df[key] >= Q1 - 1.5 * IQR) & (df[key] <= Q3 + 1.5 *IQR)
df = df.loc[filter]Com esse trecho de código, conseguimos passar em todas as features e remover os dados que estão fora dessa definição. É muito importante analisar os dados que serão removidos, em alguns cenários, realmente existem dados fora do padrão, que realmente são importantes. Dessa forma, a clássica resposta “DEPENDE” se aplica perfeitamente, quando o assunto é remover dados de outliers.
[…] Gerando uma visualização com bloxPlot, percebemos que existem outliers, e foi usado o Intervalo Interquartil para remove-los. Essa técnica foi comentado em outro post. Consulte aqui. […]