Aplicando Machine Learning no dataset sobre Doenças cardíacas
O infarto do miocárdio, ou ataque cardíaco, é a morte das células de uma região do músculo do coração por conta da formação de um coágulo que interrompe o fluxo sanguíneo de forma súbita e intensa.
Fonte: ALVES, B. / O. / O.-M. Ataque cardíaco (infarto) | Biblioteca Virtual em Saúde MS. Disponível em: https://bvsms.saude.gov.br/ataque-cardiaco-infarto/#:~:text=O%20infarto%20do%20mioc%C3%A1rdio%2C%20ou.
Prever uma possível doença cardíaca com base no histórico dos pacientes é ajudar a pessoa se cuidar antes de ter um sintoma, ou adoecer com sequelas. Analisar dados de saúde é uma ação bastante delicada, não podemos expor os pacientes de nenhuma forma, além de algumas vezes ser preciso um especialista para ajudar essa interpretação de forma mais eficaz.
Como de costume, os exemplos desse post estão no colab.
Nesse post iremos realizar o treinamento com os algoritmos: Support Vector Machine
(SVM), Random Forest (RF), Logistic Regress (LR), K-Nearest Neighbor (KNN), Decision Tree (DT). Alguns algoritmos foram executados com diferentes parâmetros para chegar em uma configuração com uma boa acurácia.
Sobre o dataset
A base de dados que vamos usar nessa abordagem esta disponível em: https://www.kaggle.com/datasets/johnsmith88/heart-disease-dataset com os seguintes dados:
| Coluna | Descrição | Valores |
| Age | Idade | 22 a 77 anos. |
| Sex | Sexo | 1: masculino 0: feminino |
| cp | Tipo de dor no peito. | 1 a 4 |
| trestbps | Pressão arterial em mm Hg na admissão ao hospital. | 94 a 200 |
| chol | Colesterol em mg/dl. | 126 a 564 |
| fbs | Glicemia em jejum maior que 120 mg/dl. | 1: verdadeiro 0: falso |
| retecg | Resultados eletrocardiográfico em repouso. | 0 a 2 |
| thalach | Frequência cardíaca máxima alcançada. | 71 a 202 |
| exang | Angina induzida por exercício. | 1:sim. 0:não |
| oldpeak | Depressão do segmento ST induzida por exercício em relação ao repouso. | 0 a 6.2 |
| slope | A inclinação do pico do segmento ST do exercício. | 1 a 3 |
| ca | Número de vasos principais coloridos por fluoroscopia. | 0 a 3 |
| thal | Dor no peito ou dificuldade para respirar. | 1: normal 2: fixo 3: reversível |
| target | Indicador se possui ou não doença cardíaca 1 | 1: sim 0: não |
Pré processamento
Removendo duplicados
Existem 1025 instâncias nesse dataset, após usar a lib profile-report foi identificado várias instâncias repetidas. Instancias repetidas pode gerar um vício no algoritmo, ja que ele não irá predizer, e sim replicar um dado visto anteriormente. Removido, usando a função do pandas drop_duplicates().
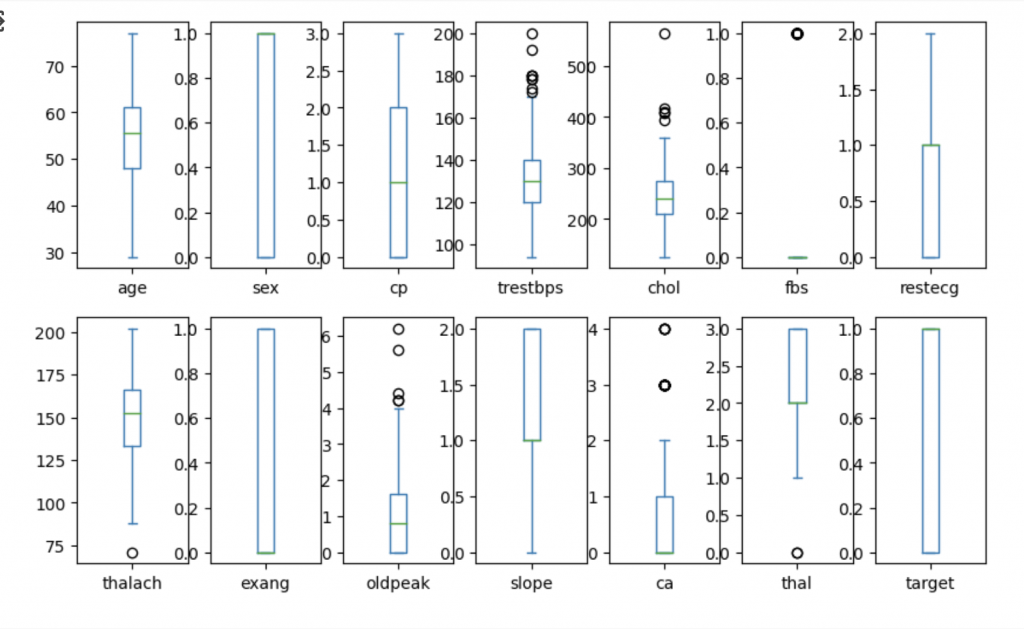
Removendo outliers
Gerando uma visualização com bloxPlot, percebemos que existem outliers, e foi usado o Intervalo Interquartil para remove-los. Essa técnica foi comentado em outro post. Consulte aqui.
Treinando os modelos
Base de testes:
É muito importante separar a base em treino e teste. Para que um dado que esteja no treino, não esteja no teste. O scikit-learn, tem uma função que realiza isso:
y = df["target"]
X = df.drop('target',axis=1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state = 0)Decision Tree:
Esse algoritmo ja foi mencionado em outro post ( consulte aqui ). Basicamente, cada bifurcação é uma decisão, e vão sendo feitas, chamadas de nó, até chegar em uma folha, que é a decisão propriamente dita.
rf = RandomForestClassifier(n_estimators=20, random_state=12,max_depth=5)
rf.fit(X_train,y_train)
rf_predicted = rf.predict(X_test)
rf_conf_matrix = confusion_matrix(y_test, rf_predicted)
rf_acc_score = accuracy_score(y_test, rf_predicted)
print("confussion matrix")
print(rf_conf_matrix)
print("\n")
print("Accuracy of Random Forest:",rf_acc_score*100,'%\n')
print(classification_report(y_test,rf_predicted))Accuracy of Random Forest: 84.78260869565217 %
Random Forest
Tem uma grande semelhança com o Decision Tree, a diferença é que de forma automatica, se realiza várias árvores, fazendo uma floresta. É uma ótima técnica quando se tem uma grande quantidade de dados e features.
rf = RandomForestClassifier(n_estimators=20, random_state=12,max_depth=5)
rf.fit(X_train,y_train)
rf_predicted = rf.predict(X_test)
rf_conf_matrix = confusion_matrix(y_test, rf_predicted)
rf_acc_score = accuracy_score(y_test, rf_predicted)
print("confussion matrix")
print(rf_conf_matrix)
print("\n")
print("Accuracy of Random Forest:",rf_acc_score*100,'%\n')
print(classification_report(y_test,rf_predicted))Accuracy of Random Forest: 84.78260869565217 %
Interessante ressaltar, que ficou com o mesmo valor que a decision tree.
Decidi então realizar variações nas árvores de decisões, principalmente no critério de classificação e na profundidade máxima.
Através de medições de quanto uma instancia pertence a uma classe, o gini faz suas decisões, ja o entropy, além disso observa também a desordem dos outros dados.
k_range = range(1,11)
scores = {}
for k in k_range:
dtFor = DecisionTreeClassifier(criterion = 'entropy',random_state=0,max_depth = k)
dtFor.fit(X_train, y_train)
y_pred = dtFor.predict(X_test)
scores[k] = accuracy_score(y_test,y_pred)
plt.plot(k_range,list(scores.values()), label='entropy')
for k in k_range:
dtFor = DecisionTreeClassifier(criterion = 'gini',random_state=0,max_depth = k)
dtFor.fit(X_train, y_train)
y_pred = dtFor.predict(X_test)
scores[k] = accuracy_score(y_test,y_pred)
plt.plot(k_range,list(scores.values()), label='gini')
plt.xlabel('Profundidade da Árvore')
plt.ylabel('% de Acurácia')
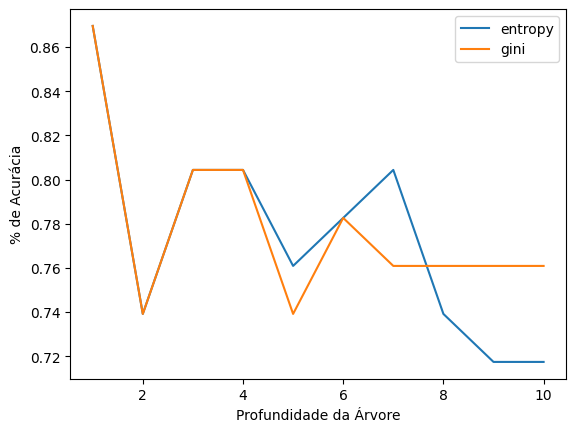
plt.legend()Conseguimos ver um gráfico, que inicia com uma ótima acurácia:
Quando exibimos a árvore visual com apenas 1 nível de profundidade, percebemos que só se observa a feature thal, que é a referente a dor no peito, algo muito previsível, provavelmente quem vai ao hospital, a chance de possuir alguma dor, é bastante alta, o ideal era observar outras features.
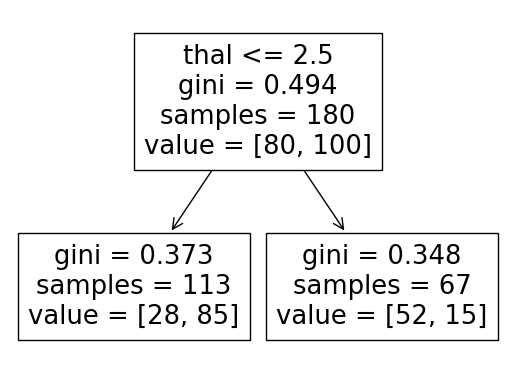
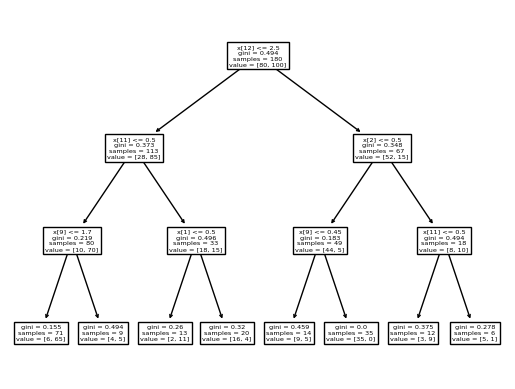
O segundo valor com uma boa acurácia, é o 3 profundidades, e ao plotar de forma visual, percebemos que existem outras observações.
K-NeighborsClassifier
Esse algoritmo analisa os vizinhos para tomar sua decisão e agrupar os dados. Possui algumas métricas, e podemos varias a quantidade de vizinhos analisados. No estudo foi usado euclidean e Manhattan, varias de 1 a 4 vizinhos, obtendo os seguintes níveis de acurácia.
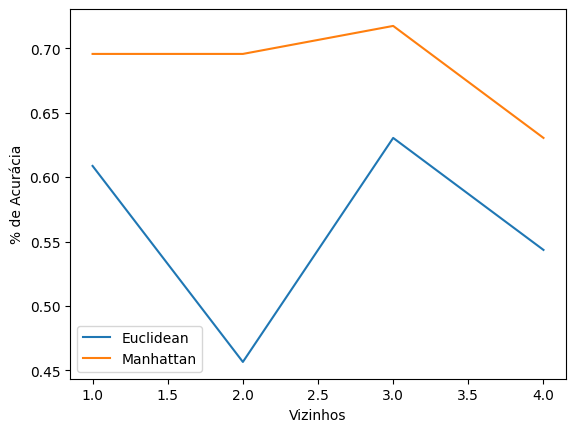
Então, usando 3 vizinhos e métrica manhattan, obtemos 71% de acurácia.
knn = KNeighborsClassifier(n_neighbors=3, metric='manhattan')
knn.fit(X_train, y_train)
knn_predicted = knn.predict(X_test)
knn_conf_matrix = confusion_matrix(y_test, knn_predicted)
knn_acc_score_1_neighbors = accuracy_score(y_test, knn_predicted)
print("confussion matrix")
print(knn_conf_matrix)
print("\n")
print("Accuracy of K-NeighborsClassifier:",knn_acc_score_1_neighbors*100,'%\n')
print(classification_report(y_test,knn_predicted))Accuracy of K-NeighborsClassifier: 71.73913043478261 %
Support Vector Classifier
svc = SVC(kernel='rbf', C=2)
svc.fit(X_train, y_train)
svc_predicted = svc.predict(X_test)
svc_conf_matrix = confusion_matrix(y_test, svc_predicted)
svc_acc_score = accuracy_score(y_test, svc_predicted)
print("confussion matrix")
print(svc_conf_matrix)
print("\n")
print("Accuracy of Support Vector Classifier:",svc_acc_score*100,'%\n')
print(classification_report(y_test,svc_predicted))Accuracy of Support Vector Classifier: 71.73913043478261 %
Logistic Regression
from sklearn.linear_model import LogisticRegression
reg = LogisticRegression( )
reg.fit(X_train, y_train)
reg_predicted = reg.predict(X_test)
reg_conf_matrix = confusion_matrix(y_test, reg_predicted)
reg_acc_score = accuracy_score(y_test, reg_predicted)
print("confussion matrix")
print(reg_conf_matrix)
print("\n")
print("Accuracy of Support Vector Classifier:",reg_acc_score*100,'%\n')
print(classification_report(y_test,reg_predicted))Accuracy of Support Vector Classifier: 91.30434782608695 %
Comparação dos resultados
Random Forest 84.7826091%
K-Nearest Neighbour (10) 60.8695652%
K-Nearest Neighbour (3) 71.7391303%
Decision Tree 84.7826094%
Support Vector Machine 71.7391305%
Logistic Regression 91.304348%
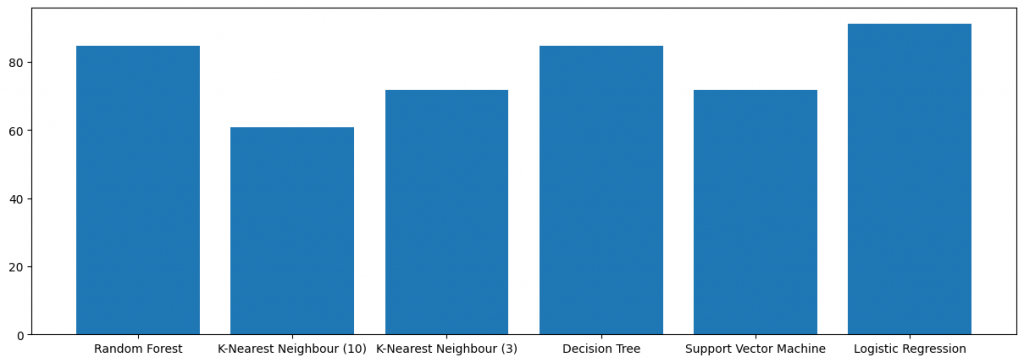
Pela característica do problema, o modelo de regressão logistica tem um resultado melhor.
Observações sobre o estudo:
Esse trabalho foi apresentado na disciplina de Aprendizagem de máquina e produzido artigo. Junto do meu colega Gerfesson. Obtivemos nota máxima.
Usamos também com referência diversos outros estudos, mas o principal foi esse, e fica a recomendação de leitura:
K. Rashid, M. A. Islam, R. A. Tanzin, M. L. Labib, and M. Khan, “Heart disease pre- diction using interquartile range preprocessing and hypertuned machine learning,” in 2022 4th International Conference on Inventive Research in Computing Applications (ICIRCA), IEEE, Sept. 2022.