Aplicando Árvore de decisão no dataset Íris
No post anterior vimos uma aplicação simples do algoritmo Árvore de decisão, para entender se iríamos ou não para universidade em um determinado dia. O nosso treino, possuía poucas linhas, e no geral tínhamos poucas decisões para tomar, era apenas IR ou NÃO IR, mas, quando o nosso conjunto de possíveis decisões aumenta, a quantidade de dados que precisamos para validar nosso modelo também tende a aumentar.
Como de costume, todo os exemplos estão no colab.
Vamos iniciar importando as nossas bibliotecas, iniciando nosso Toy Dataset Iris e transformando num dataframe do pandas.
import pandas as pd
from sklearn.datasets import load_iris
data = load_iris()
iris = pd.DataFrame(data.data)
iris.columns = data.feature_names
iris['target'] = data.target
iris.head()Para ser mais didático, e melhorar a compreensão, vamos iniciar o nosso estudo, apenas com 2 features referente a pétalas, para conseguirmos visualizar em um plano cartesiano. Em seguida adicionamos todos os campos.
irisCopy = iris.loc[iris.target.isin([1,2]), ['petal length (cm)','petal width (cm)' , 'target']]
# separa em x e y
x = irisCopy.drop( 'target', axis=1)
y = irisCopy.targetComo temos uma dataset bem grande, conseguimos dividi-lo em duas base, treino e teste. Vamos fazer isso usando o `train_test_split`.
from sklearn.model_selection import train_test_split
x_train, x_teste, y_train, y_test = train_test_split( x, y , test_size=0.30, random_state=22)Temos nossa base de teste e treino, agora vamos criar nosso classificador, usando nossa base de treino.🏋🏽
from sklearn import tree
import matplotlib.pyplot as plt
clf = tree.DecisionTreeClassifier(random_state=22)
clf = clf.fit(x_train, y_train)
fig, ax = plt.subplots(figsize=(10,8))
tree.plot_tree(clf)
plt.show()Obtemos essa árvore:
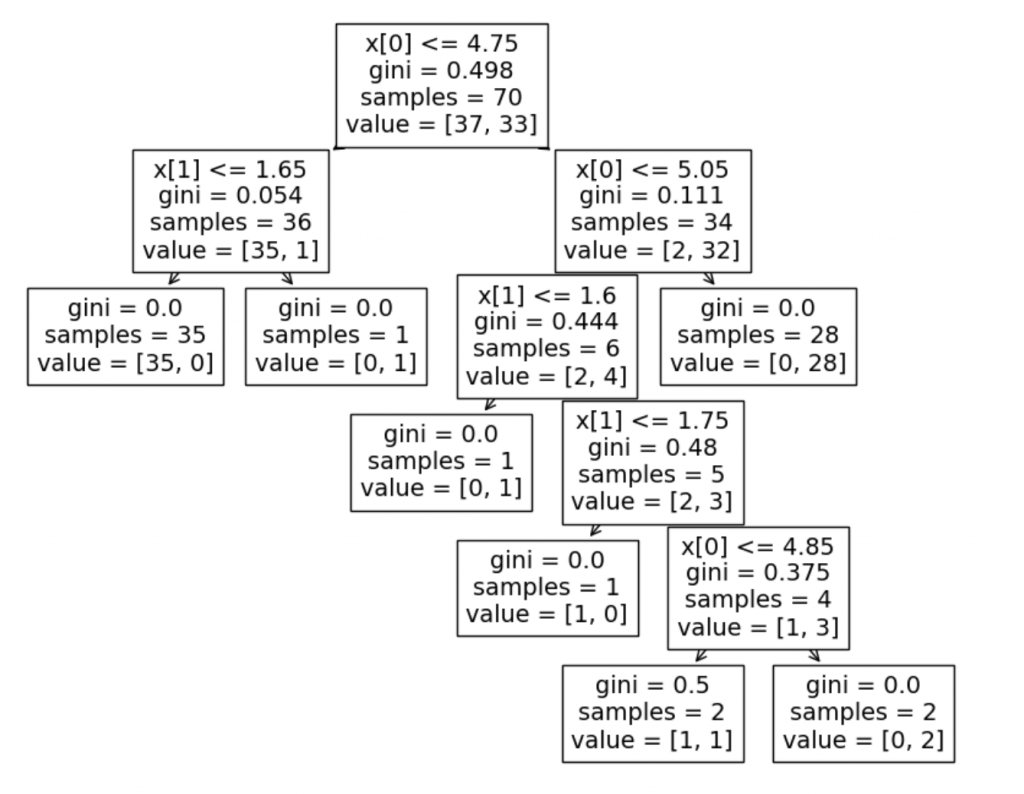
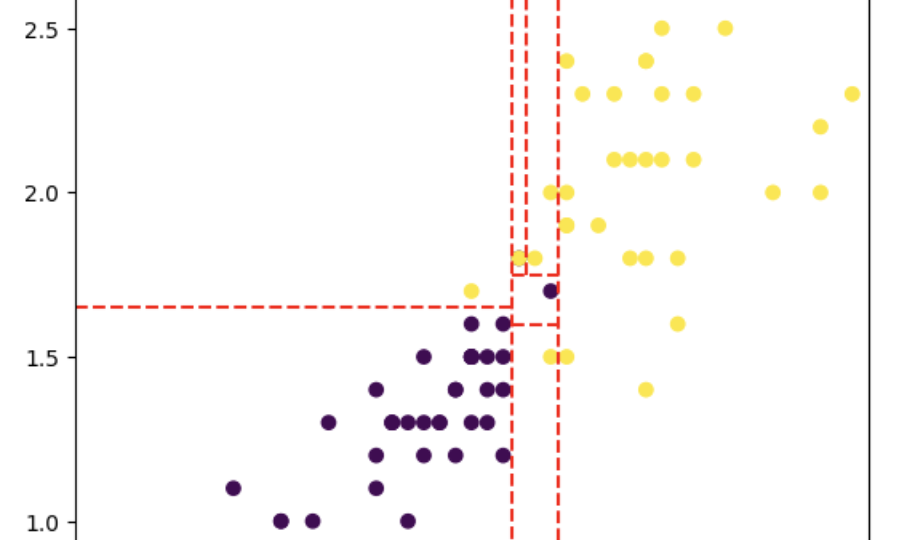
Agora, vamos analisar cada nó, as decisões que estao sendo analisadas, e baseado nisso, vamos traças linhas em um gráfico, para identificar como estão sendo feito cada decisão:
- x[0] < 4.75
- x[0] < 5.05
- x[1] < 1.65 ( nesse caso x[1], é o Y )
- x[1] < 1.6
- x[0] < 4.85
fig, ax = plt.subplots()
ax.scatter(
x_train['petal length (cm)'],
x_train['petal width (cm)'],
c=y_train
)
ax.plot([4.75,4.75], [0,3], '--r') # primeiro nó
ax.plot([2,4.75],[1.65,1.65], '--r') # segundo nó
ax.plot([5.05,5.05], [3,0], '--r') # terceiro nó
ax.plot([4.75,5.05],[1.6,1.6], '--r') # quarto nó
ax.plot([4.75,5.05],[1.75,1.75], '--r') # quinto nó
ax.plot([4.85,4.85], [1.75,3], '--r') # sexto nó
ax.set( xlim=(3, 7), xticks=[2,3,4,5,6,7], ylim=(0.9,2.7), yticks=[1,1.5,2,2.5])
plt.show()Conseguimos ver as seguintes linhas:
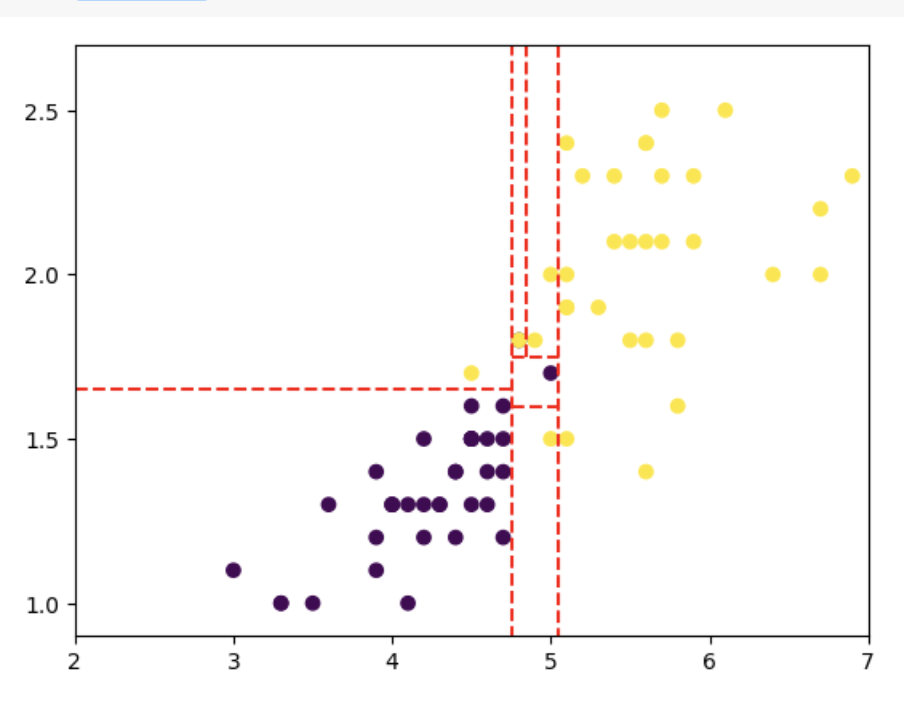
Dessa forma, podemos ver quais decisões foram tomadas pelo software. Agora, podemos evoluir, deixar de ser apenas 2 escolhas, e colocar para o algoritmo treinar todas as escolhas possíveis, ver a árvore ainda maior.
x_train, x_teste, y_train, y_test = train_test_split( iris.drop( 'target', axis=1), iris.target , test_size=0.20, random_state=10)
clf2 = tree.DecisionTreeClassifier(random_state=22).fit(x_train, y_train)
fig, ax = plt.subplots(figsize=(10,8))
tree.plot_tree(clf2)
plt.show()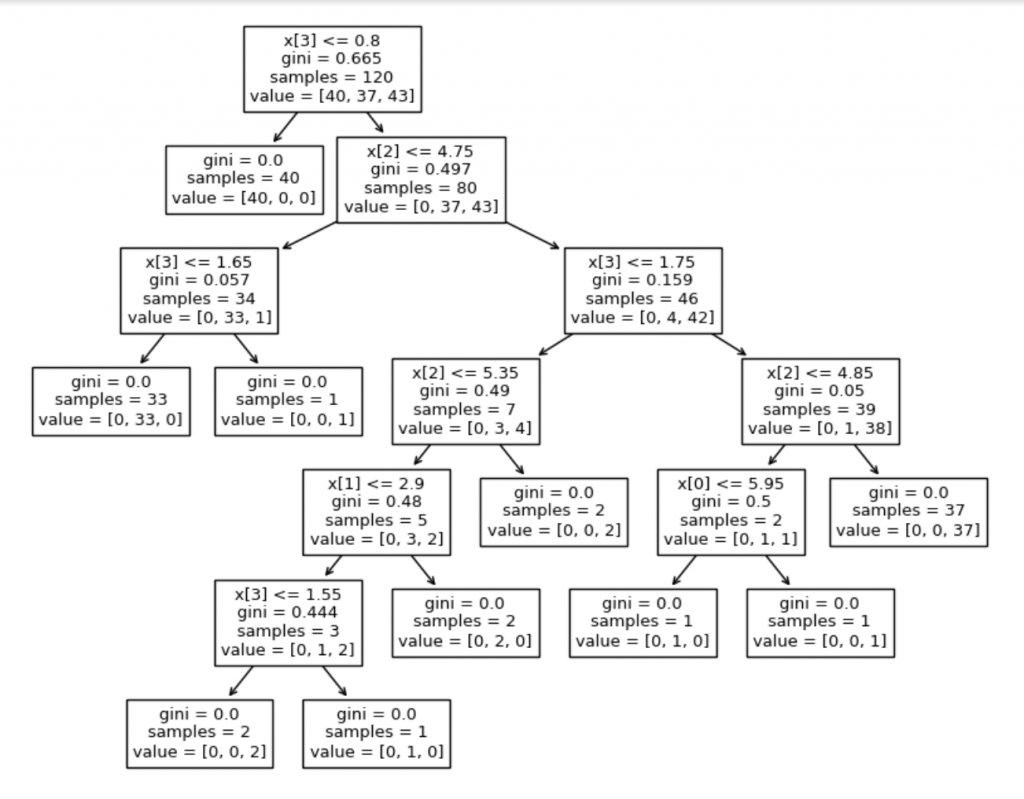
Agora, vamos avaliar nosso modelo, qual o score que ele possui:
clf2.score(x_train, y_train)
# 1Um excelente aprendizado, nota máxima. Mas essa não é a única maneira de se avaliar um modelo. Existem outras métricas, que veremos em outro post.
[…] algoritmo ja foi mencionado em outro post ( consulte aqui ). Basicamente, cada bifurcação é uma decisão, e vão sendo feitas, chamadas de nó, até […]