
Sotaques Digitais: um modelo brasileiro consegue entender o português do jeito que a gente fala?
Mandei essa frase para três LLMs:
“Véi, Brasília é tudo longe de tudo. Pra ir na padaria são 15 minutos de carro. Pelo menos as tesourinhas ajudam no trânsito.”
O Llama-3.3-70B (Meta) respondeu que tesourinhas eram motocicletas.
O GPT-4o-mini (OpenAI) ficou em cima do muro — disse que poderiam ser rotatórias ou desvios, sem convicção.
O Sabiá-4 (Maritaca AI) acertou direto: passagens de nível, infraestrutura característica do plano urbanístico de Brasília. Quem conhece a cidade sabe.
Esse foi o cenário mais revelador de um benchmark que passei semanas construindo — e que mostra por que um modelo nacional importa.
O que é o Sotaques Digitais
O Sotaques Digitais é um benchmark que criei para testar LLMs numa tarefa específica: entender o português brasileiro como ele é usado no dia a dia digital — redes sociais, WhatsApp, atendimento ao cliente, avaliações de produto.
São 90 cenários divididos em três categorias:
- Ironia (30 cenários) — sarcasmo, antífrase, ironia situacional em contextos digitais
- Expressões Idiomáticas (30 cenários) — expressões do cotidiano brasileiro contemporâneo
- Regionalismos (30 cenários) — vocabulário e referências culturais das 5 macrorregiões
Os modelos comparados:
| Modelo | Empresa | Tipo |
|---|---|---|
| Sabiá-4 | Maritaca AI 🇧🇷 | Nacional, especializado em PT-BR |
| GPT-4o-mini | OpenAI | Global, multilíngue |
| Llama-3.3-70B | Meta (via Groq) | Open source, multilíngue |
Como funciona a avaliação
Cada modelo recebeu o mesmo prompt para todos os cenários — sem dica de categoria, sem instrução extra. A instrução era simples:
“Analise o texto abaixo e explique o que o autor realmente quis dizer, considerando o contexto cultural e linguístico do português brasileiro.”
As respostas foram avaliadas pelo GPT-4o como juiz (metodologia LLM-as-a-Judge), em uma escala de 1 a 5 ancorada em gatilhos semânticos específicos de cada cenário. Por exemplo, para um cenário de ironia, o juiz verificava se o modelo detectou o tom sarcástico e não interpretou o elogio literalmente.
Todo o código está no GitHub e o dataset está disponível no Hugging Face.
Os resultados
Visão geral
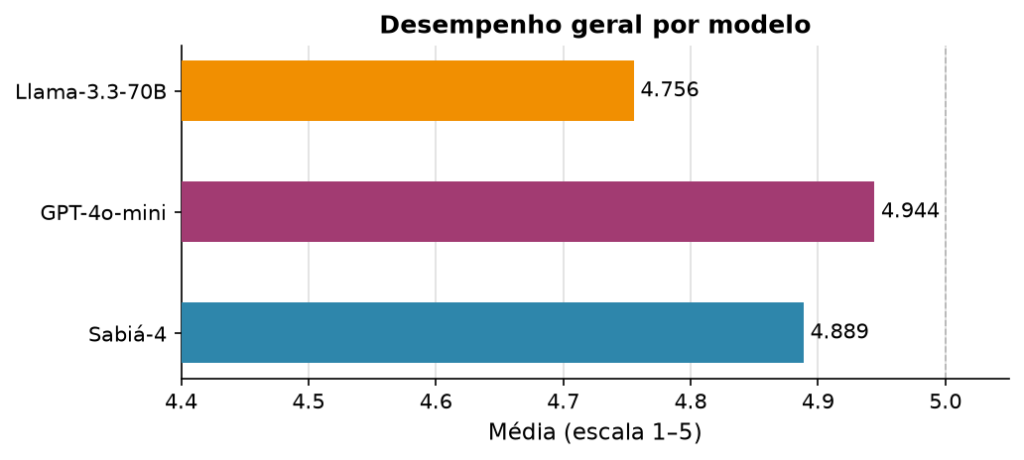
| Modelo | Média (1–5) | Desvio Padrão |
|---|---|---|
| GPT-4o-mini | 4,94 | 0,23 |
| Sabiá-4 | 4,89 | 0,44 |
| Llama-3.3-70B | 4,76 | 0,64 |
A diferença entre Sabiá-4 e GPT-4o-mini é de 0,05 ponto em uma escala de 5. Marginal. O Llama varia quase três vezes mais que o GPT-4o-mini — desempenho menos previsível ao longo dos cenários.
Por categoria
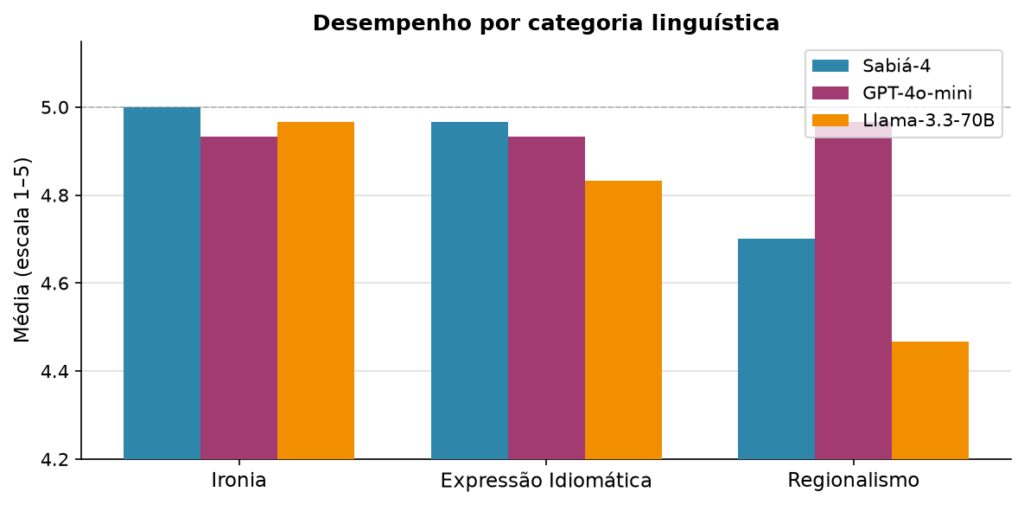
| Categoria | Sabiá-4 | GPT-4o-mini | Llama-3.3-70B |
|---|---|---|---|
| Ironia | 5,00 | 4,93 | 4,97 |
| Expressão Idiomática | 4,97 | 4,93 | 4,83 |
| Regionalismo | 4,70 | 4,97 | 4,47 |
Aqui o Sabiá-4 aparece em seu melhor momento.
Em Ironia, o Sabiá-4 atingiu nota máxima — 5,00 — superando os dois concorrentes globais. O mesmo em Expressões Idiomáticas. Em ambas as categorias, o fenômeno testado está no coração do português brasileiro informal: exatamente o tipo de dado que um modelo treinado com foco no idioma tende a internalizar melhor.
Regionalismos por macrorregião
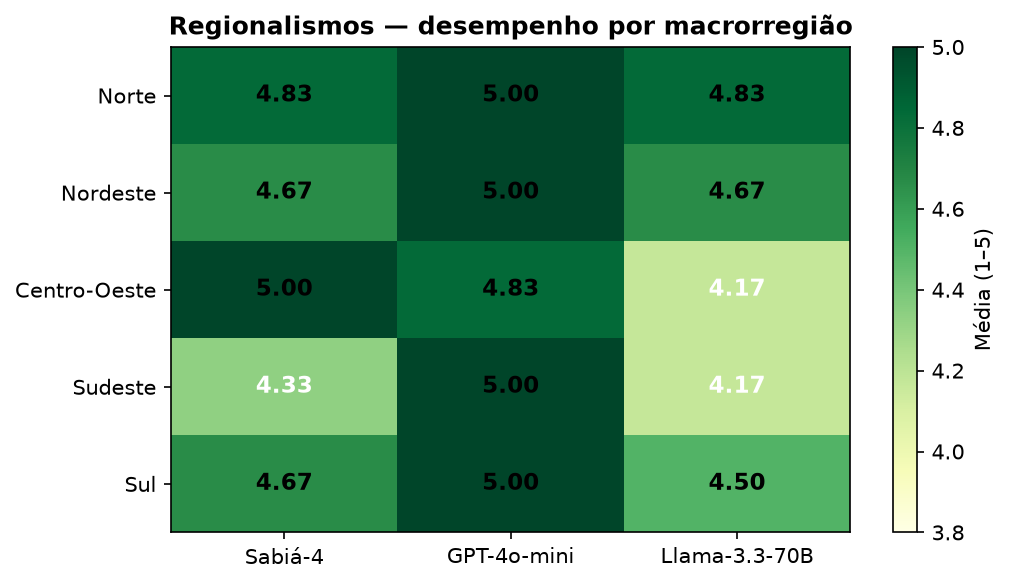
| Região | Sabiá-4 | GPT-4o-mini | Llama-3.3-70B |
|---|---|---|---|
| Norte | 4,83 | 5,00 | 4,83 |
| Nordeste | 4,67 | 5,00 | 4,67 |
| Centro-Oeste | 5,00 | 4,83 | 4,17 |
| Sudeste | 4,33 | 5,00 | 4,17 |
| Sul | 4,67 | 5,00 | 4,50 |
No Centro-Oeste, o Sabiá-4 liderou com nota máxima — exatamente a região onde estava o cenário das tesourinhas. O Llama desabou para 4,17 no Centro-Oeste e no Sudeste.
Distribuição de erros
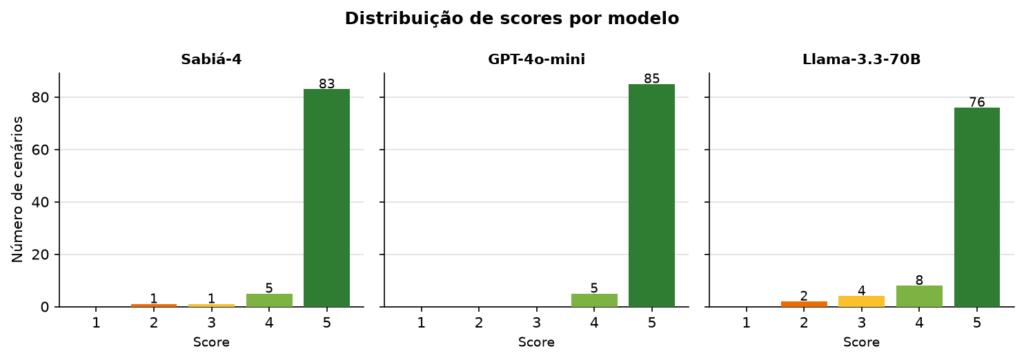
Sabiá-4 e GPT-4o-mini erraram em apenas 2 cenários cada (scores abaixo de 4). O Llama teve 6 cenários com erros.
Os casos mais interessantes
“As tesourinhas ajudam no trânsito” — só o Sabiá acertou
Este foi o único cenário em que os três modelos tiveram notas diferentes entre si, com o Sabiá-4 claramente à frente:
| Modelo | Nota | O que disse |
|---|---|---|
| Sabiá-4 | 5 | Identificou corretamente: passagens de nível do urbanismo de Brasília |
| GPT-4o-mini | 4 | Ficou em dúvida: “podem ser rotatórias ou desvios” |
| Llama-3.3-70B | 2 | Errou: interpretou como motocicletas |
Tesourinhas é um termo muito específico do cotidiano de Brasília. Esse conhecimento não aparece em grandes portais — ele vive em fóruns locais, grupos de WhatsApp, reportagens do DF. Um modelo que prioriza representação do português brasileiro tem mais chance de capturá-lo.
“O rolê de ontem foi sinistro” — ninguém acertou
O Sabiá-4 e o Llama interpretaram sinistro pelo sentido padrão — algo negativo. Mas no contexto paulistano, sinistro é gíria para “incrível”. Gírias que invertem o sentido original de uma palavra são o desafio mais difícil para qualquer modelo: elas evoluem rápido, aparecem concentradas em comunidades específicas, e o sinal de treino é pequeno.
GPT-4o-mini foi o único que acertou nesse cenário.
“Bergamota” e “de buenas” no Sul
Os modelos identificaram marcadores regionais como bah e trilegal, mas erraram em bergamota (nome regional para tangerina no Sul) e de buenas (estar tranquilo, sem problema). O contexto regional era claro — o erro foi no vocabulário específico.
O que isso nos diz
Um modelo nacional competindo com gigantes globais em seu próprio idioma é, por si só, um resultado relevante. Mas os dados mostram algo mais específico: o Sabiá-4 é melhor onde o português brasileiro é mais cultural e menos lexical — ironia, subentendidos, tom informal.
Regionalismos são o desafio mais difícil para todos. Esse tipo de conhecimento está espalhado na internet de forma fragmentada: portais regionais, grupos locais, comunidades específicas. Capturá-lo vai exigir curadoria intencional — e é exatamente o tipo de aposta que faz sentido para um modelo nacional fazer.
O Llama-3.3-70B mostrou que ter 70 bilhões de parâmetros não substitui representação cultural nos dados de treino.
O que isso nos diz
O resultado central desse benchmark é: o Sabiá-4 compete de igual para igual com modelos globais em português brasileiro, e em duas das três categorias testadas — Ironia e Expressões Idiomáticas — ele lidera.
Regionalismos foram o maior desafio para todos. A explicação mais provável é que esse tipo de fenômeno depende de conhecimento enciclopédico muito específico — saber que sinistro é elogio em SP, que tesourinhas são rotatórias em Brasília, que bergamota é tangerina no Sul. Esse conhecimento está espalhado na internet de forma fragmentada, em portais regionais, fóruns e redes sociais locais. Capturá-lo bem vai depender de curadoria intencional de dados regionais — uma oportunidade clara para modelos nacionais que priorizem essa cobertura.
O Llama-3.3-70B mostrou que ter 70 bilhões de parâmetros não é suficiente quando falta representação cultural específica nos dados de treino.
Como reproduzir
O benchmark é totalmente aberto e reproduzível. Você precisa de três API keys (Maritaca AI, OpenAI e Groq — o Groq é gratuito) e rodar:
git clone https://github.com/ramondomiingos/ptbr-irony-idioms-regionalism-benchmark
cd ptbr-irony-idioms-regionalism-benchmark
python3.12 -m venv .venv && .venv/bin/pip install -r requirements.txt
cp .env.example .env # preencher as keys
.venv/bin/python src/run_benchmark.py --dry-run # testa com 3 cenários
.venv/bin/python src/run_benchmark.py # benchmark completo
O custo total para rodar os 90 cenários nos 3 modelos mais o juiz GPT-4o é de aproximadamente $2–4.
Próximos passos
O benchmark segue em desenvolvimento. Os próximos passos são:
- Calcular concordância entre anotadores (IAA) para fortalecer a metodologia
- Expandir para 500+ cenários com mais variantes regionais e gírias recentes
- Submeter para o PROPOR 2026
O dataset está disponível no Hugging Face com licença CC BY 4.0 — qualquer pessoa pode usar, estender ou testar outros modelos com ele.
Se quiser conversar sobre o projeto, me encontra no LinkedIn ou comentar aqui no post.
Muito bom!!
O sabiá é competente mesmo, pois para dominar todos os sotaques e particularidades do português do Brasil é complicado.